Systems Design · DB
Equality-Driven HRIS
PAY-EQUITY HRIS
A redesign of a global retailer's Human Resources Information System (4,000+ stores) built around a single goal: detect and close gender- and race-based pay disparities. I designed the equitable-pay data model and the manager-facing performance and compensation dashboards, with role-based access control, audit logging, and compensation-review workflows baked in.
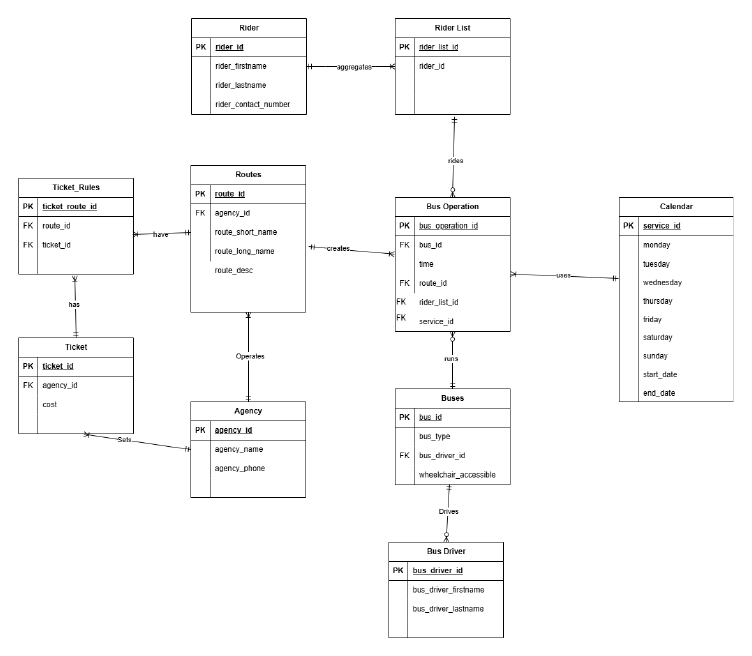
On top of the systems-design work I built the analytical layer: a SQL schema for employees, compensation history, and audit trails, and a Python pay-gap analysis (regression controlling for role, level, and tenure) that feeds the disparity flags surfaced on the dashboard.
Tools & skills
PythonSQLpandasstatsmodelsRBACAudit LoggingDashboard Design
What I learned
- Fairness has to be something you can query. A pay-equity claim is only as good as the schema and the controls sitting behind the number.
- Audit trails and role-based access aren't features you bolt on at the end. They shape the data model from the very first table.
- A dashboard only changes behavior when the metric behind it can stand up to legal and HR at the same time.